
08 Jul '26
1
0
01 Jul '26
1
0
{kind=link}
1
0
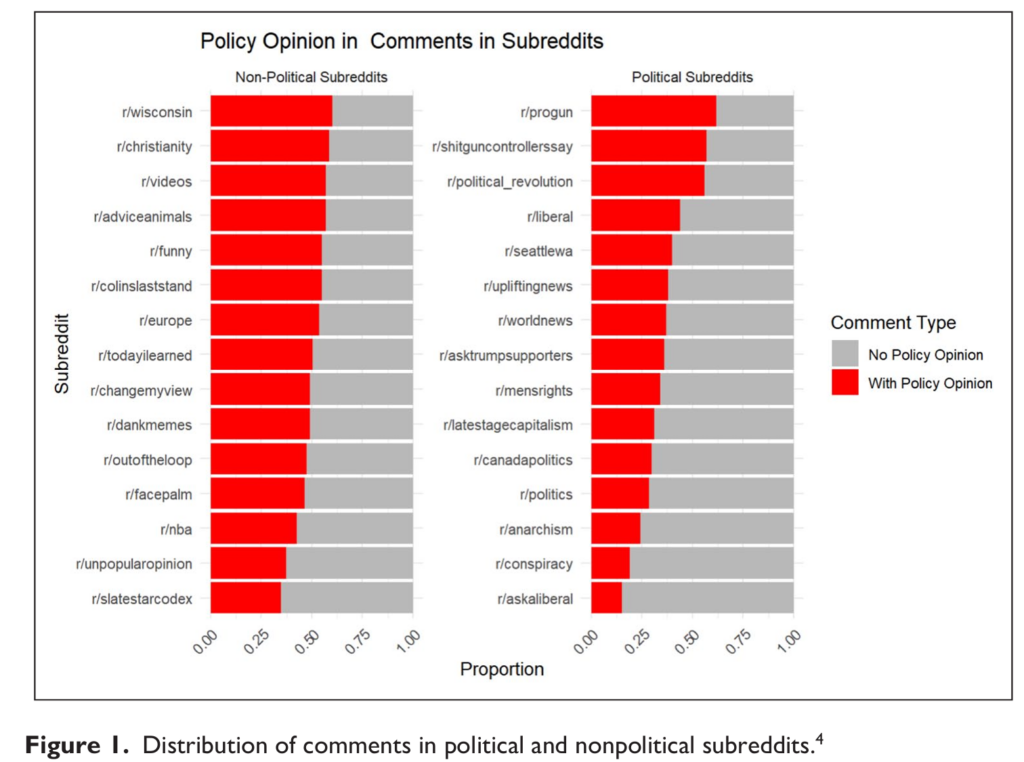
Political discussion in non-political online communities is more likely to see policy opinion expression
by Community Data Science Collective 19 May '26
by Community Data Science Collective 19 May '26
19 May '26
{kind=link}
1
0
Performing the News: Rhetoric, Trust, and the Fight Against Video Disinformation in India
by Community Data Science Collective 07 May '26
by Community Data Science Collective 07 May '26
07 May '26
1
0
Troubleshooting in Computational Research Design: Report from a Workshop Series
by Community Data Science Collective 18 Apr '26
by Community Data Science Collective 18 Apr '26
18 Apr '26
{kind=link}
1
0
{kind=link}
1
0
When AI Feels Like a Confidant: The Illusion of Shared Privacy in AI Companions
by Community Data Science Collective 09 Mar '26
by Community Data Science Collective 09 Mar '26
09 Mar '26
1
0
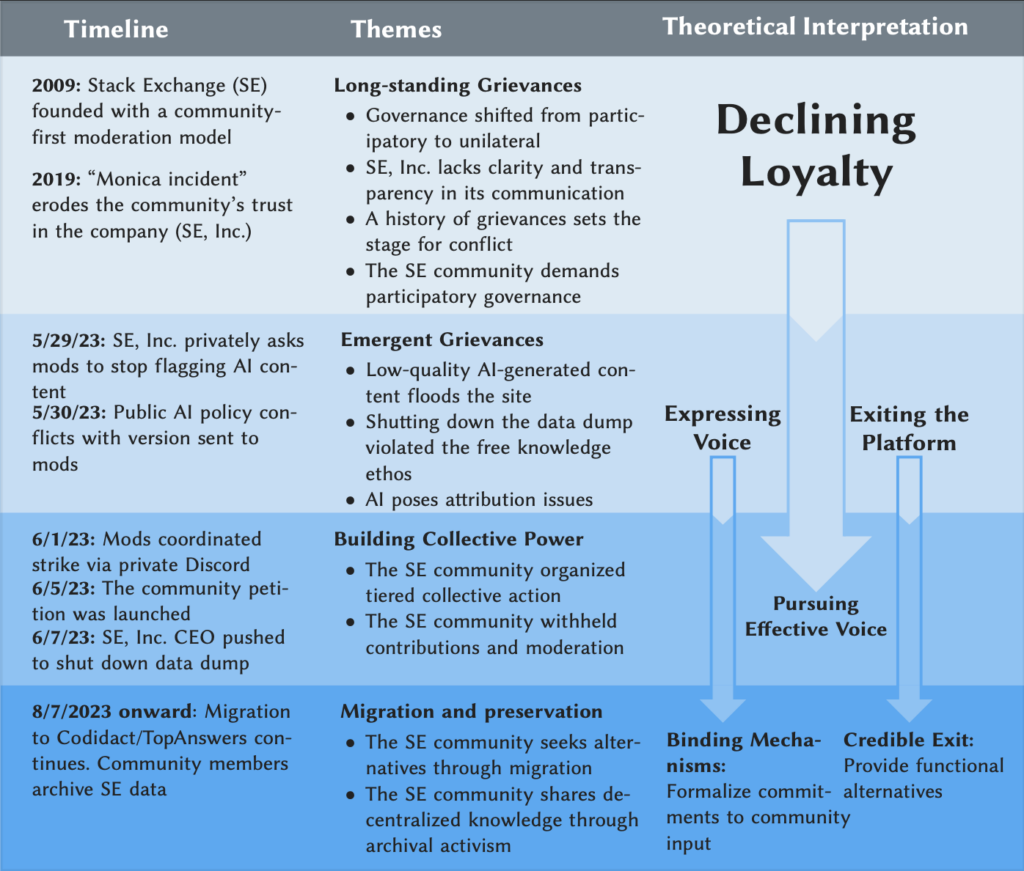
AI Didn’t Start the Fire: How Stack Exchange Moderators and Users Demonstrate Exit, Voice, and Loyalty
by Community Data Science Collective 24 Feb '26
by Community Data Science Collective 24 Feb '26
24 Feb '26
{kind=link}
1
0
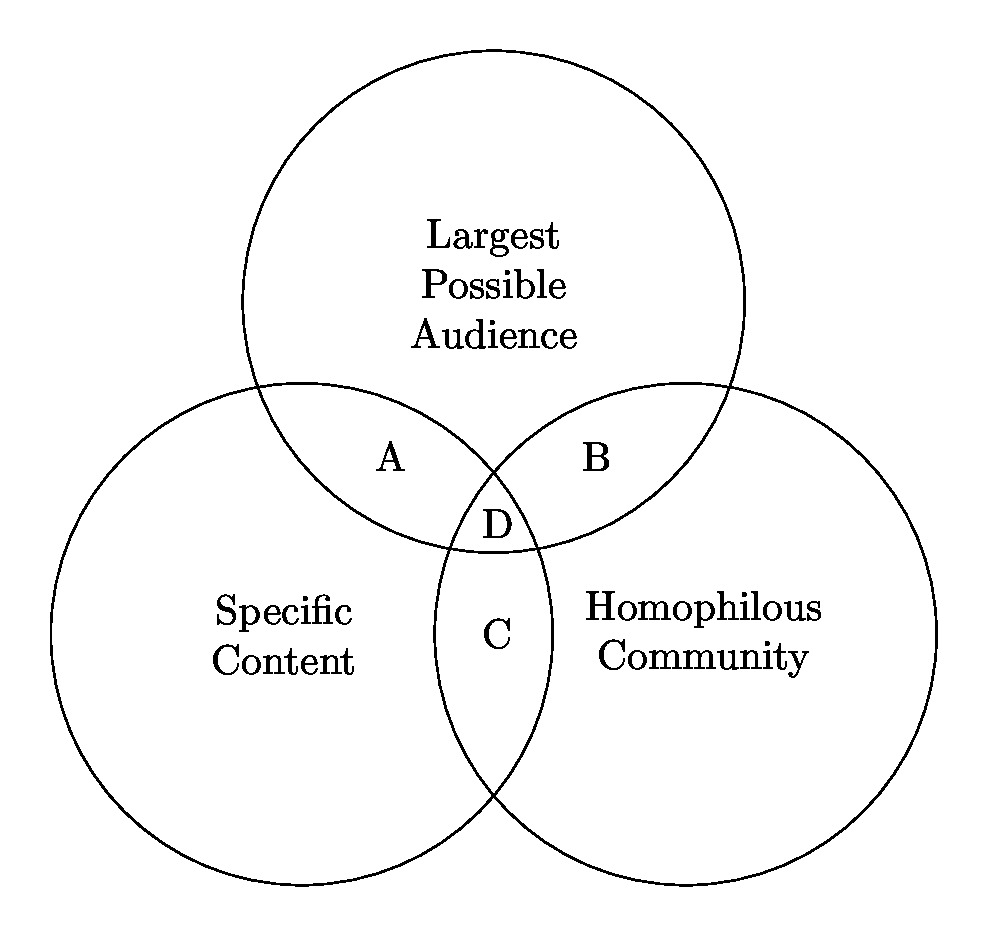
Why do people participate in similar online communities?
by Community Data Science Collective 15 Feb '26
by Community Data Science Collective 15 Feb '26
15 Feb '26
{kind=link}
1
0